d-tags
d-tags


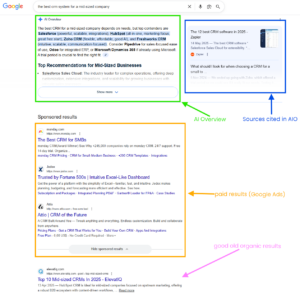
Fan-out queries, RAG, and grounding – how does the AIO mechanism work?
First, here are a few terms to help you understand how Google generates responses to user queries in the AI Overviews section.
1. Fan-out queries
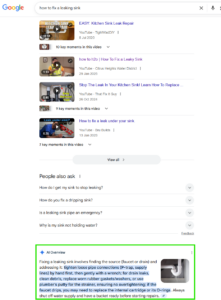
The AIO mechanism begins by breaking the user’s query into its constituent parts, known as “fan-out queries.” This involves analyzing the prompt entered and breaking it down into related phrases. How does it work in practice? You can check it out with this tool, which will show associated queries after you enter a sample prompt: https://queryfanout.ai/. Let’s say a user asks Google, “What are the best SEO agencies in Poland?” The breakdown of phrases for such a query might look like this:

Source: queryfanout.ai
In a nutshell, Google first tries to match a more complex query to related keywords.
In the next step, for these queries, the algorithm queries the Google index to retrieve data and broader context. From an exhaustive list of available sources, the system selects the most meaningful “chunks,” or fragments of text, that it can directly use to construct a response. The goal is to select sources from this exhaustive list that complement each other rather than duplicate information, which is why unique content is particularly important here.
2. RAG
The second key concept in the context of AI Overviews is RAG. This is a technique widely used in LLM tools that aims to reduce hallucinations. The idea is that the model should not “make up” answers, but should rely on reliable sources and provide answers that are as correct and contextually relevant to the query as possible.
How does it work? The RAG system is a connection between the AI model and a database – in the case of AI Overviews and AI Mode, this “database” is the Google index. In this database, we place documents that we want the model to treat as a source of knowledge for generating answers.
3. Grouding
The third concept that helps to understand how AIO works is grounding. Again, this is a mechanism designed to reduce hallucinations, but it works later. Once the model has generated a response, it reexamines the result and compares it to the content of the sources. On this basis, it verifies that the response it has prepared does not deviate from the source material in terms of content.